Gemini 3.5 Flash 深度评测:
打破速度与智能边界,全面超越 3.1 Pro

Google 在 I/O 开发者大会上正式发布了新一代大模型 Gemini 3.5 Flash。根据 Google 官方博客的声明,它在多个维度上展现出媲美大型旗舰模型的智能,同时保持了 Flash 系列一贯的速度,被定位为“迄今为止最强大的智能体和编码模型”。
传统认知里,“Flash”通常代表着轻量、快速但能力阉割。然而,Gemini 3.5 Flash 以 4 倍于同类前沿模型的速度提供前沿级性能,且成本通常不到一半,在核心测试中全面反超了前代旗舰 Gemini 3.1 Pro。本文将通过详细的基准测试对比与实操场景,带你深度解析这款模型究竟强在哪里。
一、核心性能表现:多项指标超越前代旗舰与竞品
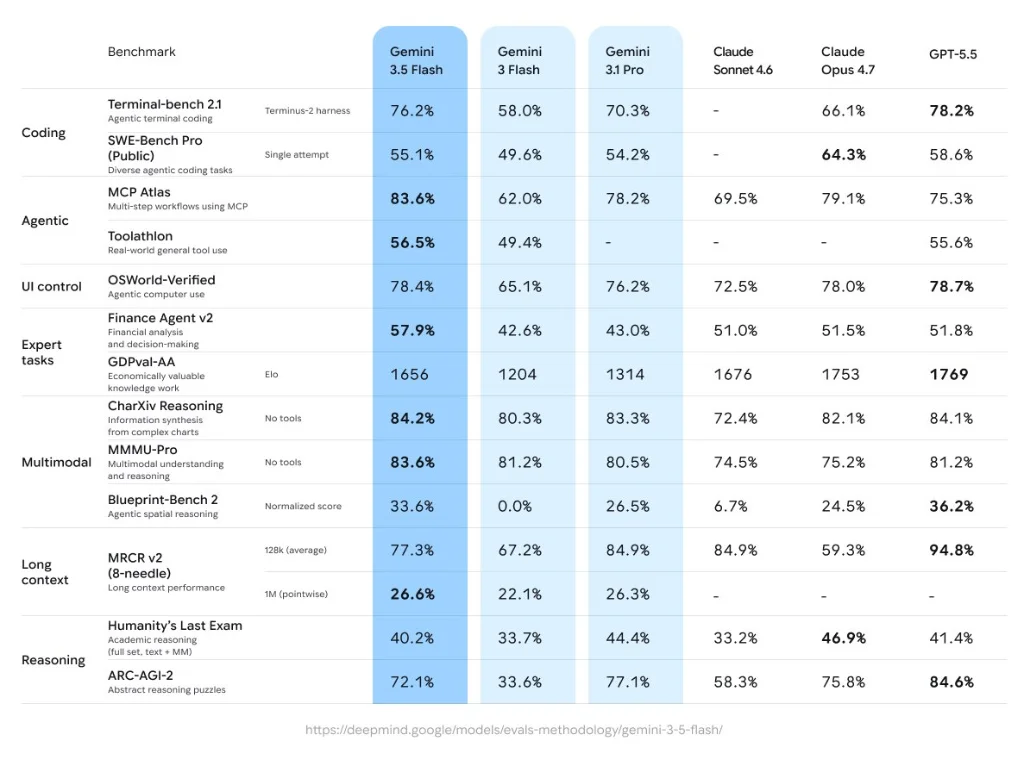
Gemini 3.5 Flash 打破了“轻量模型性能弱于旗舰”的传统定位,在多个面向实际业务场景的测试中取得了令人瞩目的成绩。尤其在复杂的 Agent 工作流和代码编写能力上,它甚至超越了许多业内顶尖的主流模型。
| 测试基准 | Gemini 3.5 Flash 得分 | 对比竞品表现 |
|---|---|---|
| MCP Atlas (多步 Agent 工作流) | 83.6% | 超过 Gemini 3.1 Pro (78.2%)、GPT-5.5 (75.3%) 和 Claude Opus 4.7 (79.1%) |
| Terminal-Bench 2.1 (代码能力) | 76.2% | 超过 Gemini 3.1 Pro (70.3%),接近 GPT-5.5 (78.2%) |
| SWE-Bench Pro (真实软件工程) | 55.1% | 超过 Gemini 3.1 Pro (54.2%) |
| MMMU-Pro (原生多模态推理) | 83.6% | 超越所有对比主流旗舰 (GPT-5.5 为 81.2%) |
| GDPval-AA (经济价值知识工作) | 1656 Elo | 大幅超越 Gemini 3.1 Pro (1314) |
从以上数据可以看出,Gemini 3.5 Flash 在涉及复杂多步骤代理(Agentic)、空间推理(OSWorld-Verified 达到 78.4%)以及信息图表合成理解(CharXiv Reasoning 达到 84.2%)等高难度领域,已经具备了全面接管核心业务逻辑的能力。
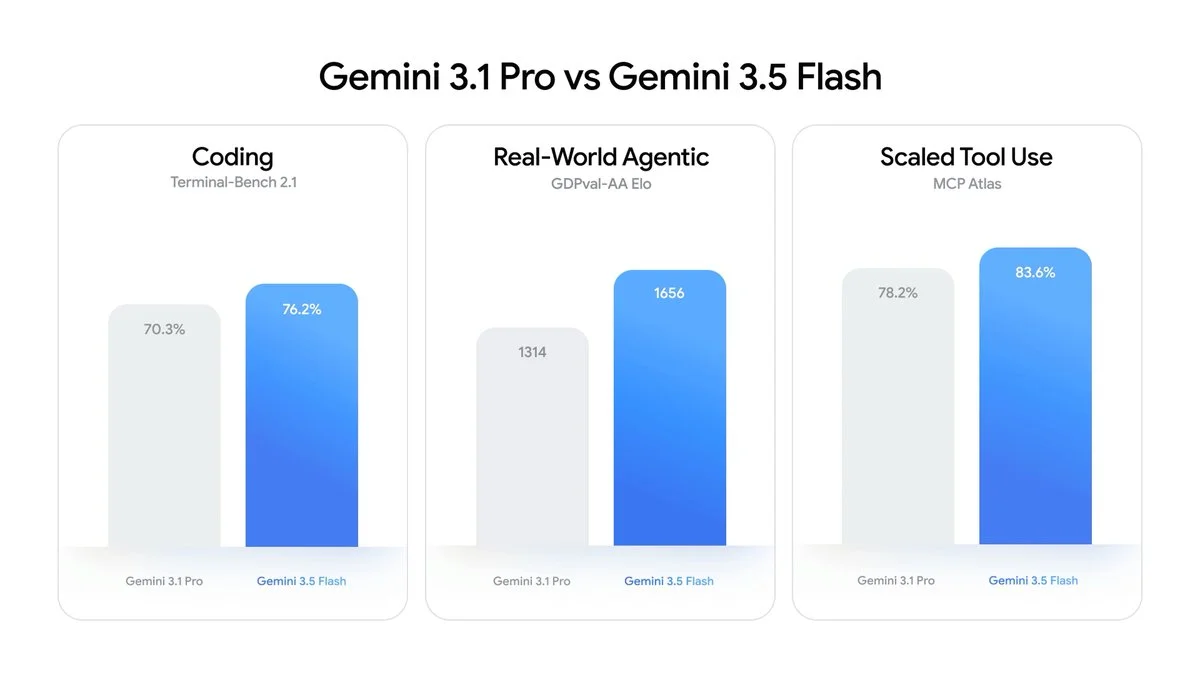
二、速度与交互:接近实时的 4 倍速提升
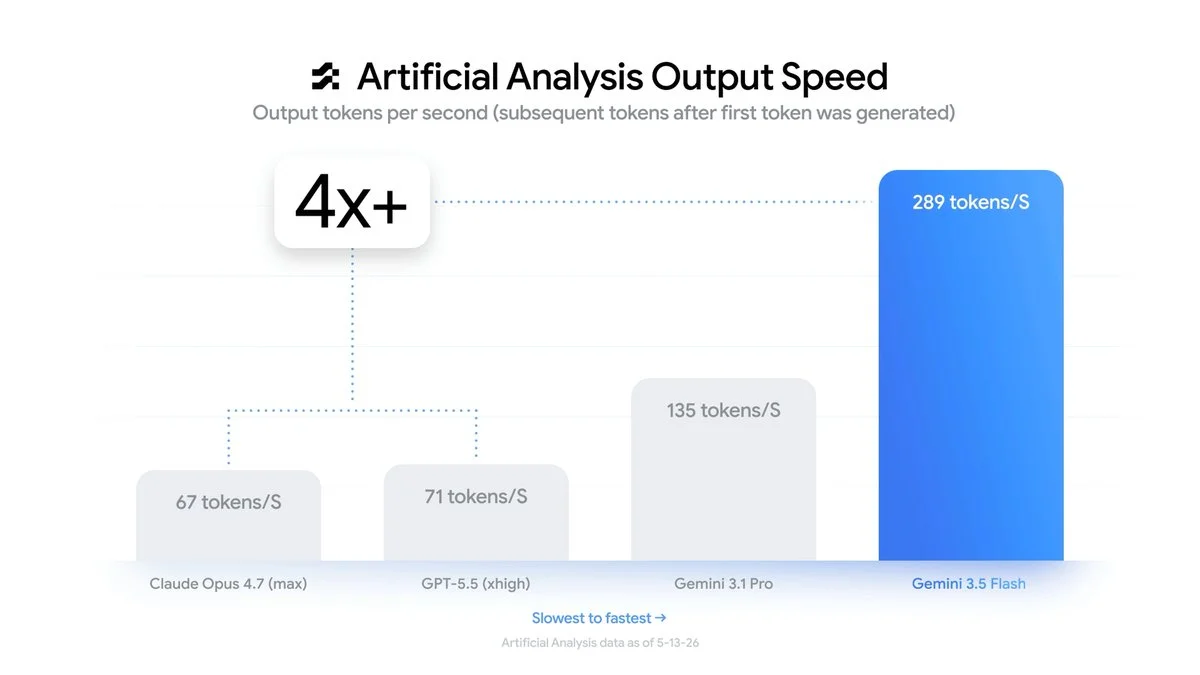
除了惊艳的基准得分,Gemini 3.5 Flash 最突出的护城河是“速度”。官方的 Artificial Analysis Output Speed 数据显示,它的输出速度达到了恐怖的 289 tokens/秒,首 token 延迟极低。
直观对比:相比于 GPT-5.5 (71 tokens/S) 和 Claude Opus 4.7 (67 tokens/S),Gemini 3.5 Flash 足足快了 4 倍以上。即便是前代自家的 Gemini 3.1 Pro,也仅有 135 tokens/S。
在实际体验中,这种速度提升带来了质的飞跃。以往调用前代模型处理复杂开发流时,可能需要等待 8-10 秒的思考和吐字;现在只需 2-3 秒即可全量返回。有开发者反馈,在 IDE 插件中进行跨文件代码重构时,原本需要漫长等待的 Agent 工作流,现在能够做到“即问即答”,极大地缩短了心流中断的时间。
三、百万 Token 级长文本处理与开发场景
作为被官方盖章为“最强大的编码模型”,Gemini 3.5 Flash 延续了超大上下文的优良传统,支持 100 万 token 的上下文窗口(约 75 万个英文单词或数万行代码)。
在长文本测试(MRCR v2 8-needle)中,它在 128k 窗口下取得了 77.3% 的优异成绩。你可以直接将一个中等规模的 Web 项目源码、数千页的 API 文档,或是整个 GitHub 仓库打包丢给它,让它帮你排查深埋的 Bug 或梳理架构。
Agent 工作流质变
极高的生成速度让基于多步思考的 Agent 不再拖沓。在执行“分析日志-定位文件-生成修改方案-执行验证”这类闭环时,效率显著优于传统的旗舰模型。
纯原生多模态代码支持
遇到 UI 还原问题,无需借助外部 OCR,直接截图贴给 Gemini 3.5 Flash 即可精准生成对应的前端组件代码,这得益于其 83.6% 的 MMMU-Pro 多模态推理能力。
四、价格与性价比:极低的调用成本
如果说能力媲美旗舰让人心动,那么它的定价策略才是真正的“大杀器”。Google 明确表示,它的成本通常不到同类前沿模型的一半。
虽然相比于前几代的纯入门 Flash 模型(如 2.5 Flash),3.5 版本的绝对 API 价格有所上调(输入 1.5 美元/百万 token,输出 9 美元/百万 token),但相较于它所能替代的 3.1 Pro、GPT-5.5 或 Claude Opus 4.7 而言,它便宜了惊人的 40% 到 70%。
这意味着,初创团队和独立开发者可以毫无顾虑地将原本舍不得交给旗舰模型的重度文本处理、批量客服质检、全站爬虫内容提取等任务,全量交给 Gemini 3.5 Flash 跑批处理。
五、Gemini 3.5 Flash 真的完美无缺吗?(已知局限性)
没有任何模型是完美的。通过深度研读基准数据和实测反馈,我们也发现了它在某些极限场景下的短板,这些是你在架构选型时必须知道的“代价”:
局限一:极限深度推理天花板
在 Humanity’s Last Exam(人类终极考试)和 ARC-AGI-2(抽象深度推理)中,Gemini 3.5 Flash 的成绩分别为 40.2% 和 72.1%,均低于前代旗舰 Gemini 3.1 Pro(44.4% 和 77.1%),也低于 GPT-5.5 的 84.6%。这意味着在极其前沿的数学、物理证明或极限逻辑推理题中,它仍然比不上纯正的超大旗舰。
局限二:满载百万 Token 时的衰减
在极限 100 万 token 填满的点对点精准召回测试(MRCR v2 1M pointwise)中,其准确率会断崖式下降至 26.6%(虽然同级模型也表现不佳)。因此,如果需要 100% 精准提取超大文件的某个冷僻细节,仍需结合 RAG(检索增强生成)技术辅助。
如果你在调用 API 期间遇到地区报错等网络阻碍,请务必参考我们整理的 Gemini 提示目前不支持你所在地区解决办法。
六、常见问题解答
Q.Gemini 3.5 Flash 和 Gemini 3.1 Pro,我到底该选哪个?
对于 95% 以上的日常使用、代码编写和 Agent 自动化流,无脑选 Gemini 3.5 Flash。它的速度快了 4 倍,代码通过率更高,且成本低得多。只有在解决极为复杂的科研、极限逻辑证明时,才需要考虑切换到更高阶的 Pro 模型。
Q.它真的比 GPT-5.5 和 Claude Opus 4.7 强吗?
在“代理能力(MCP Atlas)”和“原生多模态(MMMU-Pro)”上,Gemini 3.5 Flash 确实实现了超越;在代码基准(Terminal-Bench 2.1)上则互有胜负。但别忘了,它的核心杀手锏是:以不到一半的成本和 4 倍的速度,打出了同梯队的水平。性价比是它的最大优势。
Q.国内如何稳定使用和开通 API 额度?
由于 Google 的严格区域限制,国内开发者直接访问经常遇到“出了点问题”或被封号。建议准备纯净的海外节点环境。如果作为开发者缺乏稳定的网络支持,可将其视为备用方案,并阅读相关 国内使用指南 排查网络环境。
七、核心要点总结
- 极速体验:289 tokens/秒的输出速度,比同类旗舰模型快 4 倍,极大提升了 Agent 交互和代码补全的顺畅度。
- 性能越级:在 Terminal-Bench、MCP Atlas 等测试中超越了前代旗舰 Gemini 3.1 Pro,重新定义了“Flash”轻量级的能力上限。
- 性价比之王:成本不到前沿大模型的一半,是批量自动化工作流和初创团队降本增效的绝佳选择。
- 极限短板:在面对人类极限考试(HLE)和极端抽象推理时,能力仍略逊于传统超大旗舰模型。
关于作者:陈知远
独立 AI 工具研究者,深度体验 Google Gemini 系列产品超过 2 年。专注于 AI 工具使用技巧、订阅攻略和效率提升方法的研究与分享,所有内容均基于长期使用与实际场景整理。